
Updated:
Updated: Cloud
For the GOTO EDA Day London I gave a keynote with the cheeky title: I made everything loosely coupled. Will my app fall apart?. In serverless cloud land, apps are unlikely to fall apart. But occasionally the question arises whether decoupling, especially through the insertion of intermediates, increases your cloud bill. Time to take the Architect Elevator down (and back up) to have a closer look.
It’s always about coupling
Loose coupling is a major consideration when building distributed systems. One could write whole books about coupling and its role in distributed system design. Many of the Integration Pattern forces relate to coupling. Over a decade ago, I defined coupling as follows:
Coupling describes the independent variability of connected systems, i.e., whether a change in System A has an effect on System B. If it does, A and B are coupled.
A few important corollaries complete that statement:
- Coupling isn’t binary—two systems aren’t just coupled or uncoupled. There are many nuances and shades of gray.
- Coupling has many different dimensions, from location coupling (hard-coded IP addresses) to data format coupling (small or big endian, character encodings) or temporal coupling (synchronous requests).
The second point is aptly captured in my favorite (you can tell from the gesture) slide from my re:Invent talk on distributed systems:

Design time and run-time coupling
Two dimensions of coupling are particularly pronounced:
- Design time coupling determines the extent to which a functional change in one component necessitates change in other components.
- Run-time coupling describes the impact that an operational change, such as a failure, intermittent failure, or increased latency has on other systems.
Common data types and stable interfaces are popular ways to reduce design time coupling whereas asynchronous messaging and circuit breakers are often employed to reduce run-time coupling.
TANSTAAFL: Decoupling has a cost
In my re:Invent talk I also highlight that decoupling systems has a cost .

For example, decoupling through common data formats necessitates translation at the endpoints, incurring run-time and memory cost. Location decoupling through a registry requires an additional lookup operation and message routing is often handled in a central Message Broker that incurs a run-time cost and latency.
So, in a way we should not be surprised that decoupling also comes at a cost in the cloud. Still, our reaction might be different when we see the actual cost in our monthly bill: is it really worth it? Let’s look at a real example that I was working through.
Serverless decoupling: Sending events
In a serverless workshop I spotted the following code (abbreviated for clarity—the objects have many fields):
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table(DYNAMODB_TABLE)
event_bridge = boto3.client("events")
domain_object = # set fields
table.put_item(Item=domain_object)
domain_object_status_changed_event = # set fields
event_bridge.put_events(
Entries=[{
'Time': get_current_date(request_id),
"Source": SERVICE_NAMESPACE,
"DetailType": "DomainObjectStatusChanged",
"Detail": json.dumps(domain_object_status_changed_event),
"EventBusName": EVENT_BUS
}]
)
The code is simple enough–you don’t need to be an AWS serverless expert to follow what it does. The snippet of Python code receives an incoming request from an API Gateway (not shown here), performs some logic, and then stores the business domain object in a DynamoDB table. It also publishes an event to EventBridge, AWS’ serverless event router, to inform other components of the change. Sending an event avoids direct coupling to any components interested in the change.
An architecture diagram shows the interactions as follows:
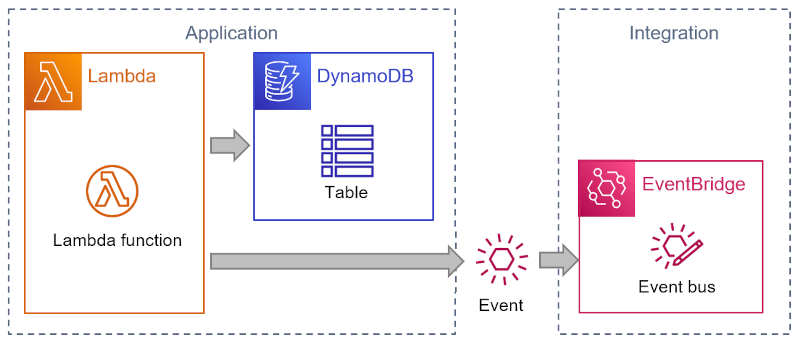
This code has several advantages:
- It gives the Lambda function control over the event format
- It is simple and minimizes the number of run-time components
- It decouples event receivers from the sender and the sender’s data internal structure, avoiding the trap of Shared Database
However, it also has some downsides:
- The application dependencies, e.g. which event is sent to what location is buried in the application code. To know the source of an event (for example to add a field), you’d have to follow the environment variable
EVENT_BUSand, short of reviewing the source code, assume that the function that’s receiving that variable is sending events to that bus (distributed tracing tools like X-Ray can also help). - Writing to the database and sending the message aren’t in one transactional scope. A failed database insert could likely be handled with an exception or by checking the return code. But if sending the event fails, you have a bigger problem as the DB update is already completed. You could either retry sending the event or undo the database insert and return an error to the caller. In either case, you’d end up writing a fair bit of extra code or face inconsistencies in your system.
Let the platform do the heavy lifting: DynamoDB Streams
The great thing about serverless is that it isn’t just a run-time for your code. It’s a complete suite of fully managed services that can reduce the need for custom code. To show the power of such a platform, I started documenting serverless refactorings that replace application code with automation code (and the corresponding resources).
The application above is an ideal refactoring scenario: rather than write source code to send an event, you can have DynamoDB send the event for you. DynamoDB Streams are a nifty feature that publishes change logs for use in other systems. That’s perfect for our use case!
Using Streams, we can eliminate all application code that prepares and sends events from our application. However, the Stream isn’t actually sending events—it has to be read from a Polling Consumer. That’s also why EventBridge cannot get events from a DynamoDB Stream directly. But AWS Lambda can and so does the recently (re:Invent 2022) released EventBridge Pipes :
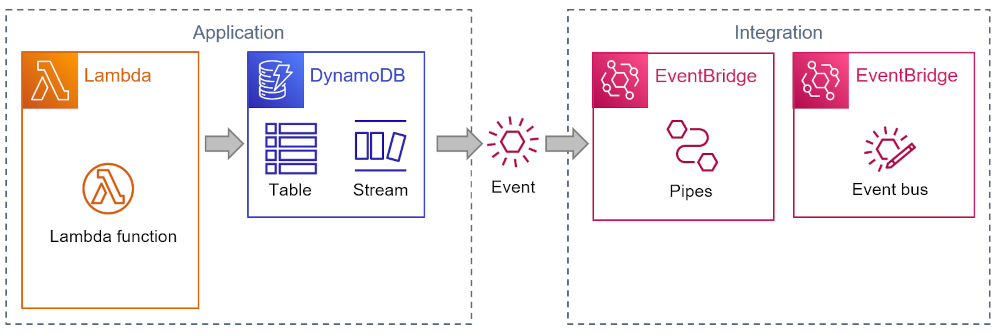
Pipes in turn, can publish the event to a variety of targets, including EventBridge. In Sync or swim parlance, Pipes acts as a Driver.
Pipes comes with another handy feature: Message Transformation. We’ll want this, as the event format published by the DynamoDB stream uses the DynamoDB data structure and therefore isn’t suitable as a business domain event (data truncated for readability):
{
"version": "0",
"id": "89961743-7396-b27b-1234-1234567890",
"region": "ap-southeast-1",
"detail": {
"eventID": "faae270c2d33f15567451234567890",
"eventName": "INSERT",
"eventSource": "aws:dynamodb",
"awsRegion": "ap-southeast-1",
"dynamodb": {
"ApproximateCreationDateTime": 1675870861,
"Keys": {
"object_id": {
"S": "usa/anytown/main-street/152"
}
},
"NewImage": {
"object_last_modified_on": {
"S": "08/02/2023 15:41:00"
},
"address": {
"M": {
"country": { "S": "USA" },
"number": { "N": "152" },
"city": { "S": "Anytown" },
"street": { "S": "Main Street" }
}
},
"contract_id": { "S": "d4745ecb-ac96-4764-ba88" }
},
},
"eventSourceARN": "arn:aws:dynamodb:ap:12345:table/xyz/stream/"
}
}
You can build the transformation with EventBridge Pipes’ handy transformation editor:
![]()
Thanks to Pipes, the event sent to EventBridge looks just like the one sent originally by the application code:
{
"version": "0",
"id": "7ba242f7-5a2c-81d3-1234-1234567890",
"detail-type": "ContractStatusChanged-Pipes",
"source": "unicorn.contracts",
"account": "1234567890",
"time": "2023-02-08T16:06:56Z",
"region": "ap-southeast-1",
"detail": {
"object_last_modified_on": "08/02/2023 16:06:56",
"property_id": "usa/anytown/main-street/153",
"contract_id": "25a238b6-3143-41e2-1234-1234567890",
"contract_status": "DRAFT"
}
}
I configured Pipes to set a different detail-type, so I can tell the events apart ( the console doesn’t yet allow setting EventBridge target parameters, so I set them from the command line).
Trade-offs
Architecture is the business of making (conscious) trade-offs, so it behooves us to look at which trade-offs this solution implies.
- The solution trades application code for platform services. Those services are likely configured using automation code, either document-oriented (JSON/YAML) or object-oriented (CDK). Automation code configures infrastructure as opposed to executing imperative statements. The resulting automation code is therefore generally less error-prone.
- Writing automation code requires deeper knowledge of the cloud platform and its features. Staying in familiar territory might be one reason why developers fall back into writing logic explicitly rather than using the platform.
- Creating the event in application code gives you more control over the data format than you might have with DynamoDB Streams, which are limited to fields that are persisted in the database. Refactoring (or tuning) your internal database can therefore become visible to other components, meaning they are coupled.
- Using platform services gives you better data consistency across database updates and event publishing as DynamoDB streams manages the event publishing.
- As mentioned above, the refactored solution makes the application topology explicit. You no longer depend on passed-in environment variables to understand which component talks to which others.
- Some developers or architects might wonder whether using more of the platform also increases “Lock-in”, i.e. your potential switching costs. That might not be the case—have a look at my recent blog post on serverless lock-in.
The new solution feels more elegant, or dare I say “cloud native”? There’s no code to send an event and no need to include the EventBridge library in the Lambda function (or learn its API). The AWS run-time takes care of transactional integrity and retry logic and does so asynchronously, making your Lambda function smaller and faster.
Show me the money: Will my cloud bill go up?
But how much does the new solution cost? Will my cloud bill go up because I used an additional service? It may but the cloud bil isn’t the only cost you should consider.
In most regions EventBridge Pipes pricing ranges from $0.40 to $0.50 for 1 million events, so your bill will contain a charge for this. Reading from DynamoDB streams carries a charge, however there’s no charge when you consume them from Lambda or Pipes.
A smaller and faster Lambda function offsets a portion of the Pipes cost.
On the flip side, the Lambda function got smaller and faster thanks to eliminating all EventBridge code. To estimate how much that would save, I did a rather non-scientific test by invoking the function several times from Postman through the API gateway that was provisioned with this code. Looking at the Lambda function metrics, I could see that the original version that sends the event explicitly bottomed out at around 65 ms (blue dot on the left). Letting DynamoDB handle the event gets it down to about 14 ms (on the right bottom)–a 75% reduction thanks to DynamoDB working asynchronously:
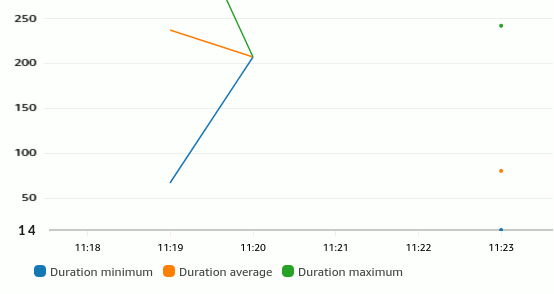
How much is that 50 milliseconds of Lambda time worth? Lambda functions cost $0.000016667 per GB-second (you get a volume discount after 9 Billion GB-seconds per month; there’s also a per request charge that doesn’t impact our comparison). It’s not easy to internalize so many zeros, so let’s do some quick math:
$0.000016667 per GB-second
$0.016667 per GB-millisecond for 1 million requests
$0.10416875 for 50 ms at 128MB for 1 million requests
So, our napkin math (based on empirical data) allows us to estimate that the shorter Lambda execution time amounts to about 1/4 of the Pipes cost (I didn’t check the reduction in memory footprint, which could further reduce the cost).
Don’t blame the light
So, did decoupling the sending of the event cost you? Sticking with the napkin figure of an additional $0.30 per million requests, a developer spending 1 hour (at $150) coding, testing, and debugging the event publishing code (remember retries and error handling!) would equate to half a billion events. If you’re not running one of world’s premier e-Commerce sites, that’s a lot of events.
And, as explained in the chapter “It’s Time to Increase Your ‘Run’ Budget” in Cloud Strategy, remember that you pay for development effort not in actual cost but in opportunity cost, i.e. the value that the developer could have created in the 1 hour. In a well-functioning software delivery organization that value should be a high multiple of the loaded salary cost. That means you’ll easily be in the billions of events.
Also, we aware that seeing cost in the cloud can have what I call the “basement effect” (described in the same chapter):
When you put brighter lights in the basement, you may see a bigger mess than before. Don’t blame the light.
So, don’t blame the cloud for making costs visible. Any application code that you run incurs infrastructure cost; you just don’t see it until the next hardware order. In my favorite example (described in The Software Architect Elevator), the vast majority of an application’s CPU and memory was spent parsing XML and garbage collection the myriad objects that it created. That did cost a ton of money, but the cost was buried in hardware procurement (the topic came to light when moving the application to an elastic infrastructure).
It’s good to look at cost, but make sure that you consider the total lifetime cost of a solution, which includes time spent debugging and trouble-shooting data inconsistencies, upgrading code to a new run-time or updating libraries, ramping up new developers, longer build and test cycles, and so on. Considering too narrow a scope is a frequent reason that people (mis-)perceive costs as going up. Architect zoom in and out, so make sure you zoom out to the right level:
Just because visible costs go up, doesn’t mean your total costs go up. Rather the opposite: you can now see and manage the costs.
Asynchronous, but latency still matters
When changing a system’s run-time architecture, cost isn’t the only consideration. For example, performance characteristics might also be affected. We already noted a reduction of the Lambda execution time by about 50ms, which will be appreciated by the Web front-end driving this sample application.
However, will sending the event asynchronously increase the time it takes to publish the event? We should generally optimize synchronous execution times (in our case the Lambda function and the API Gateway that fronts it) even if they cause longer asynchronous execution times.
To know how much we’re trading the synchronous 50ms for, Luc van Donkersgoed published a comparison of AWS serverless messaging latencies (just the 50th and 90th percentile shown here):
P50 P90
SNS Standard 73 ms 125 ms
EventBridge 148 ms 241 ms
DynamoDB Streams 213 ms 341 ms
We can see that DynamoDB streams are at the higher end of the spectrum, likely because they use a polling / pull model. More on that below.
Reconsidering Boundaries
Architecture is about boundaries, whether we’re talking about software architecture or physical (building) architecture. In the diagram above I quietly defined a boundary between “application” and “integration”:
This might appear as a natural separation of duties—you could almost say that the service icons are grouped by color. As I have observed before, though, showing the architecture as a set of service icons often doesn’t tell the whole story and can even lead to mental lock-in.
Considering the service intent as opposed to their color leads to a slightly different view. Considering Pipes as part of the application actually makes more sense as it depends on the private data source, the application database:
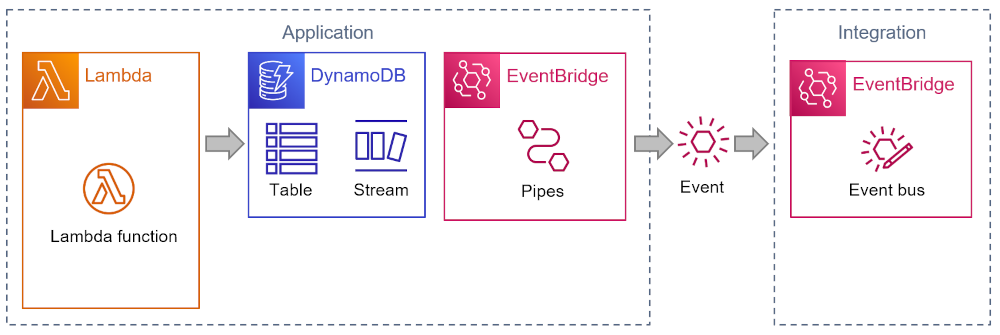
An Outbound transform is a common element in an architecture that uses a Canonical Data Model, making sure that published messages (incl. events) don’t leak implementation details into the message bus:
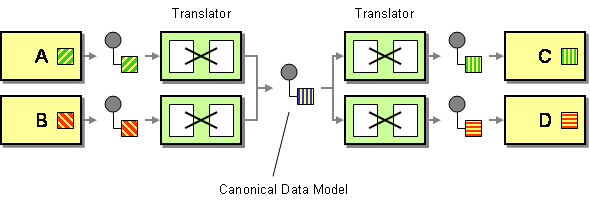
The more common pattern is called Intercepting Filters, documented in Deepak Alur, John Crupi, and Dan Malks’ seminal book Core J2EE Patterns. The “Filters” part of the pattern name refers to the Pipes and Filters architectural style. I blogged about outbound and inbound filters back in 2005. It also doesn’t go unnoticed that we’re implementing the Filter using a service called Pipes.
Following my own advice to draw architectures with the patterns in the foreground and the services as decoration, we arrive at the following picture.
![]()
Just for kicks, I did include the Sync or swim decoration aka “noses” to show which component “pushes” or “pulls” events. This way we can enrich the diagram to include relevant distributed design considerations without adding clutter.
One more thing: Do we even need an event broker?
To put the cherry on the distributed system cake, we should ask one last question:
If we use Outbound Filters and assume we have high levels of automation, do we still need an event broker?
That’s an excellent question and I’ll refer you back to API308 for some thoughts on this design decision (with yet a different gesture):

Based on that comparison, adding Pipes near the endpoints and routing events via Amazon SNS as a Publish-Subscribe Channel might be a viable architecture and actually reduce your run cost: there’s no notification charge from SNS to Lambda and data is billed at $0.09 per GB, that’s 1 million messages of 1 kB each. Since it’ll vary with the size of your messages, I invite you to complete the math but it sounds like a pretty good deal to me. Also, you gain the ability for a higher fan-out (more subscribers for a type of event) and avoid a potential development bottleneck by having to configure an event broker for each event type to be routed.
So, we find that:
Making everything loosely coupled (or thinking carefully about your architecture) can actually make your cloud bill go down.
Conclusion
This post got a bit longer than I had planned for my thoughts about a few lines of code. But as always there’s a lot to be reflected upon:
- Cost doesn’t mean just reading your billing statement and adding the numbers. Instead, you must consider the total cost of a solution and the trade-offs that are implied by the different approaches.
- The complexity of a design decision isn’t measured in lines of code. A single line can introduce dependencies or make critical assumptions. As architects, we want to understand the structure of our solution, not just the lines of code.
- Serverless gives us a lot of choice in application architecture: you can send an event from code, from a DynamoDB Stream, to an EventBridge router or to an SNS channel, or straight to another Lambda. And all that with just a few lines of automation code. Does that make architecture more relevant? Oh, yes!
- Distributed systems need special consideration. You’re not just wiring some random stuff together, you’re defining your application’s topology. Boundaries matter. Pattern diagrams help you express those decisions better than just a collection of service icons.
- Some design concepts like event pushers and pullers pass the test of time—the original post on Sync or Swim is from 2006.
Architecting for the cloud, especially fine-grained serverless applications, is awesome. It also requires new considerations. I look forward to your reactions and thoughts—please share and discuss on social media.