
Updated:
Updated: Cloud
Interest in Domain-driven Design (DDD) has surged in recent years, as indicated by popular events like DDD Europe and books such as Learning Domain-Driven Design. While modeling complex business domains has always been instrumental in successful systems, modular run-time architectures (e.g., microservices applications) requiring clear domain boundaries has given DDD a rocket booster.
Domain modeling isn’t limited to business domains, though. Technical domains, such as modern run-time or cloud architectures provide flexibility and powerful tools but can also burden developers with additional complexity. That’s why such system require expressive modeling of their domain, a task that is too often neglected.
DDD and EIP
Eric Evan’s seminal book Domain-Driven Design placed DDD firmly on the radar of modern software delivery. Eric’s book launched the same day as Enterprise Integration Patterns at OOPSLA 2003 in Anaheim. Perhaps this wasn’t a complete coincidence as books share more than might be apparent. EIP’s pattern catalog of 65 integration patterns builds on a strong underlying domain model that provides a language to describe asynchronous messaging systems. The model is structured into two tiers, with umbrella entities like Message Construction or Message Transformation grouping patterns such as Command Message or Content Filter. Along the horizontal axis, the model follows the lifecycle of a message from endpoint construction through routing, transformation. Both axes are represented in the overview diagram:

Over time we augmented the EIP domain with additional considerations, such as a push vs. pull model for message passing. So, EIP is very much based on DDD for the technical domain of message-oriented systems.
March is not a number
Eric and I have known each other for over 20 years and had various chats about domain models and library / API design. Eric used an example library that modeled time and money as a teaching tool in the early days of the JDK when the classes for data and time handling were quite weak. Developers from that era will remember missing distinctions between a date (which is time-zone independent) and a date-time (which must indicate the time zone) and abominations like representing a date with a date-time structure where the time is set to zero (that blows up the latest once you support multiple time zones).
One of my chats with Eric led to my bold statement (and blog post) that March is not a number (most of the insights were Eric’s; I mainly wrapped it with a punchy slogan).
Although mapping a domain concept like month to an integer number might seem convenient for simple date math, it hints at a lack of domain modeling.
We already know that convenience isn’t an -ility, and if you wonder what March then is: it’s a range comprising 31 days.
Let’s fast-forward two decades to the era of cloud computing, serverless applications, and automation. With so much cool stuff going on, we surely had sufficient time to tackle those pesky domain oddities? Well, if representing an important domain concept like a month as an integer number was a really bad idea, then typing complex cloud resources as strings might mean that we have some domain modeling work still ahead of us (and, no, I am not willing to accept the argument that all URIs being strings makes this the modern way).
Language shapes design (and probably thinking)
Domain languages are important because, like other languages, they give you the vocabulary to express your thoughts. There’s a common notion that language also shapes your thoughts, but I am only partway through Hayakawa’s Language in Thought and Action, so I’ll defer deeper insights until I make myself smarter.
In the familiar (and ever so slightly more structured) context of IT transformation, I did observe a fairly clear linkage between an organization’s mindset and the language being used, meaning that you make an educated guess at an organization’s digital maturity just by listening to the vocabulary being used. My book Cloud Strategy elaborates one specific example of the words being used to describe IT projects:
Absolute terms like “budget” or “headcount” are an indication of the organization assuming that it’s operating in a steady state that affords it predictability. Organizations that have embraced economies of speed, in contrast, are much more likely to use relative terms like “burn rate” or “velocity”.
You can see the side-by-side comparison of the vocabulary in my Architect Elevator Talk and AWS’ Economies of Speed eBook:

Although the widely used example of Eskimos having some 50 words for “snow” was likely misinterpreted, language does reflect mindset, so choosing your domain language wisely is much more than just a design nicety. Back to modern cloud architectures…
Towards a domain language for distributed systems
Modern cloud applications like serverless applications are distributed. And they often communicate by exchanging messages and events. That short description doesn’t sound particularly contentious, does it? So is it even worth creating a domain model for it?
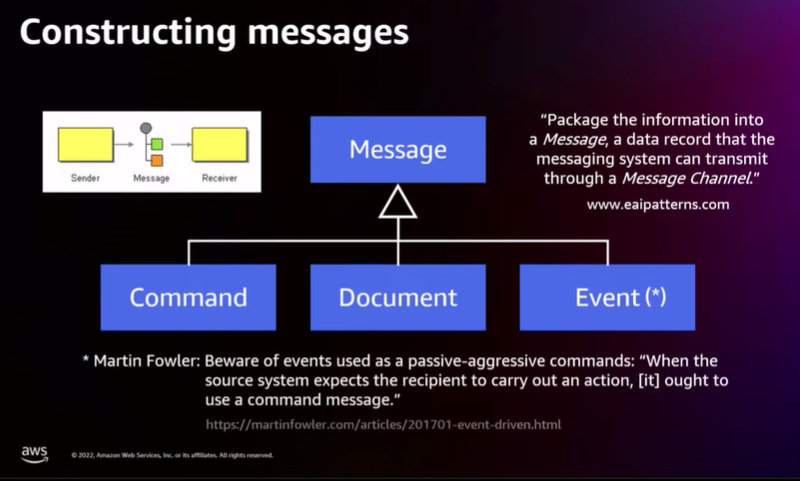
This model, which is once again from my re:Invent Talk API308, is simple (like most good models) but brings clarity or at least a point of view into frequent, and occasionally heated, debates. For example, quite a few folks contrast eventing, which they associate with Publish-Subscribe Channels, against messaging, which they see as being tied to Point-to-Point message queues. So, in their world messages and events are very different things that live on opposite ends of the integration spectrum.
The model above, in contrast, represents both commands and events as kinds of messages, meaning eventing is messaging. Behind that mental model lies the assumption that Pub-Sub vs Point-to-Point is a matter of messaging transport whereas Events or Commands describe the semantics of a message passed over such a transport. In that world, event vs. command and Pub-Sub vs. Point-to-Point are independent considerations. It’s easy to see that without a domain model, you could be going back and forth on this for a long time (it’s also a good example of how architects see more dimensions).
Although I surely have my preference (and 20 a year head start to fall back on), a model isn’t there to separate right from wrong but to clearly state your view of the world. Also note that the domain model above uses an object-oriented style (in UML notation) to express the is a relationship between event and message.
The astute reader noticed the weasel word “towards” in the section heading, which translates into me not trying to actually present a complete domain model for distributed systems, but rather just some thoughts on it. So, let’s turn our attention to the place where many modern distributed systems live: the cloud.
Cloud Vocabulary != Service Catalog
When tackling complex domains like cloud computing or distributed systems, the language you choose matters. I commented before how technical abstractions depend on a simpler language, so let’s explore this interesting intersection of abstraction, domain models, patterns, and language.
When I spoke at re:Invent about lock-in (indeed not an easy thing to pull off), I highlighted the risks of adopting the cloud provider’s language as your only vocabulary:
Thinking only in the cloud vendor’s services mentally locks you in.
Mental lock-in is both subtle and severe as you might not even realize that you’re thinking with a specific vocabulary that affects your reasoning. To level the discussion a bit, I have seen people who’ve been equally mentally locked in by thinking only in CNCF project names, with the main difference being one extra level of indirection between marketing budgets and developers.
When translating cloud service names into a vendor-neutral and well-structured domain language, we may find that there’s a good bit of work to do as domain concepts are often hidden inside the services. When poking at cloud services I like to stay close to my (professional) home, so if anyone get offended, I can offer to fix it (I am also being extra picky for argument’s sake, so hopefully no one is offended in the first place).
An Example: Serverless Integration
So, let’s look what language is used to describe popular integration services. I am close to Amazon EventBridge, which comes in Event Bus and Pipes flavors. I use them merely merely as examples–most cloud providers include message channels and routers in their service portfolio.
What’s the difference between Buses and Pipes? The EventBridge overview docs provide the following description:
EventBridge event buses are well suited for many-to-many routing of events between event-driven services. EventBridge Pipes is intended for point-to-point integrations between these sources and targets…
This description makes a distinction between many-to-many routing vs. point-to-point integration, implying that many-to-many routing is well-suited for events. For Pipes, the type of message isn’t spelled out, but the absence of the word event might hint that it’s better suited for command messages. Whether many-to-many routing equates to Pub-Sub isn’t clarified in this context, but the detailed docs clarify that buses provide a Recipient List for small fan-out. Interestingly, a Recipient List is commonly associated with command messages due being a central control point, which contrasts to a Publish-Subscribe Channel allowing recipients to sign up freely (given appropriate permissions).
If I wanted to be snarky, I’d throw in my comment from my EDA Day Keynote that a transport or router can’t make applications event-driven. Only the applications can decide whether they want to be driven by the events that they receive. But to our own defense, EventBridge only states that it’s well suited, so we should let that pass.
Distributed systems: Control Flow, Batching, Partial Failures
Taking modeling the technical domain of distributed systems and message routing a step further, we quickly find that it isn’t limited to message semantics (events, commands, messages) and transport models (pub-sub, recipient list, point-to-point). Reliable and performant messaging systems (like we find them in the cloud) must consider control flow, batching of events, retries, and error handling. EventBridge is no exception. Let me summarize the differences between Buses and Pipes in more detail:
Pipes polls for events whereas a Bus is an event sink that another services pipes (pun intended!) events into. Both services can pass messages to asynchronous services like SNS or to synchronous, rate-limited services like an API Gateway or API destinations. For the latter. both services rely on flow control. An EventBridge Bus uses a queue to store incoming messages that have to wait for downstream processing. Because Pipes polls for messages, it doesn’t need a queue but can reduce the polling rate through back pressure. Pipes also supports batching of events to make polling and processing more efficient. It can even split batches into individual messages for targets that don’t process batches. But batching messages forces you to watch out for partial failures, where some messages in a batch fail. Retrying whole batches can lead to duplicate message processing, requiring idempotency.
I’ll stop here for two reasons. For one, as part of my day job I have a detailed blog post on EventBridge Pipes batching behavior in the works. But more importantly describing these essential features in prose isn’t very effective, as anyone who has dug through the docs could confirm. What’s needed is a structured domain model that has a clean vocabulary of concepts and their relationships. These concepts are essential to understanding the dynamic run-time behavior of integration services, yet they seem to be scattered around i the documentation.
A Domain model for control flow
To keep the size (and the cognitive load) of this post in check, let’s dig deeper into just one aspect, control flow. Control isn’t a new topic by any means, allowing us to fall back on an EIP blog post from 2015, inspired by a paper from Ivan Gewirtz dating back to 2006. In this paper Ivan introduces an intuitive notion to describe pushing vs. pulling of messages:
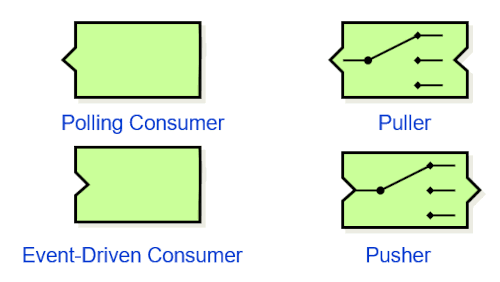
A Polling Consumer has a little nose on the left (assuming data flows from left to right), indicating that it actively pulls messages from a source. In contrast, an Event-Driven Consumer would have a little notch, suggesting that it’s passively looking for messages to be sent its way.
Following a Pipes-and-Filters composition style, one would expect to see the corresponding outbound noses and notches on the right, as shown on the right-hand side of the diagram (all four combinations are shown in the blog post).
Once again, we use a very simple (and in this case visual) model that clearly expresses a key characteristic of the messaging systems domain. Equipped with this domain model, let’s see how we can make some of the EventBridge narrative above more expressive.
To pick a simple example, let’s assume you want to move messages from an SQS queue to CloudWatch logs, AWS’ logging system. This would seem simple enough until you realize that SQS requires a consumer that is actively polling (i.e. a Polling Consumer) whereas CloudWatch logs receive events as an Event-Driven consumer. So, you have notches at both ends and hence need a connector with two “noses” to connect these pieces. We call suich a piece a Driver. EventBridge Pipes is a Driver, so can visualize the end-to-end control flow as follows:
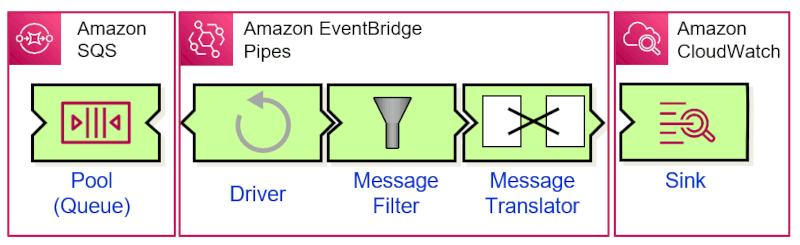
I convened myself of the EIP Icons to express the (simplified) functionality inside EventBridge Pipes, which includes a Message Filter and a Message Translator. The Driver isn’t an EIP icon as its purpose pertains to the control flow and the EIP icons focus on data flow. As the name suggests, a Driver pulls messages from a passive source and pushes them to a passive message receiver—perfect to form the missing link between SQS and CloudWatch logs!
The bonus of using a visual domain model is that even if you aren’t very familiar with push and pull control flows and EventBridge Buses vs. Pipes, you could have just looked for the “thing with two noses” and correctly selected EventBridge Pipes as the connector instead of digging through documentation.
In user interface parlance, the noses and notches are called an affordance. As “DX” has become a popular word to toss around these days, we are well advised to translate successful UX concepts like affordances into the DX world. Type systems make great affordances. More on that soon. Sadly, too many developer experiences still look like Don Norman’s masochist tea pot.
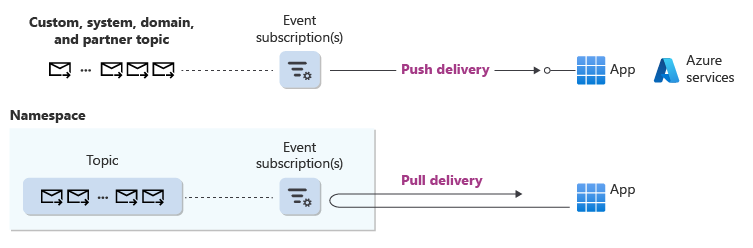
Also, to give credit where it’s due, Azure Event Grid documents include a fairly cohesive description of push vs pull control flow. Perhaps we can suggest the the nose & notch notation to them:
DDD in cloud automation–still an emerging discipline?
Alright, so we made it from DDD and EIP via dates and timezones, to transformation and economies of speed, linguistics and domain languages, messages and events, serverless integration with EventBridge, integration patterns and control flow, Pushers and Drivers, and DX affordances. Sometimes I feel that each blog post could be an entire book… if I only had more time to write!
One more important topic is left, though: automation aka IaC (Infrastructure as Code). My book Cloud Strategy contains a chapter titled “IaaC- Infrastructure as Actual Code”, which hints at my view that there’s a lot more to automation than deploying infrastructure. I’ve gone as far as stating that:
Cloud without automation is just another data center.
Developers of cloud automation tend to congregate in one of two distinct camps: those who prefer document-style automation (largely represented as a YAML document or in TerraForm syntax) and those who favor an object-oriented programming language (mainly using CDK or Pulumi). If automation code (in any form) is the best way to describe cloud solutions, then this code should express important domain concepts, right?
The reality shows that there’s still ample room for improvement (and I’m working on improving it). Sticking close to home, let’s look at the CloudFormation structure for EventBridge Pipes (shortened) as a YAML document:
Type: AWS::Pipes::Pipe
Properties:
Description: String
Name: String
RoleArn: String
Source: String
SourceParameters:
PipeSourceParameters
Target: String
TargetParameters:
PipeTargetParameters
The Pipe’s messages source is represented as a, hold it right there, string. Using strings as universal types is such a widespread issue that Kevlin Henney has a name for it:
Stringly typed
I saw a slide once titled “The most commonly used domain concepts” and two large words on it: string and int. Unfortunately I couldn’t dig that up anymore, but it captures the gap between domain modeling and every-day coding very well.
Strings are admittedly powerful. After all, URLs are strings that brought us the internet and ARNs (Amazon Resource Names) are essentially URIs for AWS resources. But they aren’t the most expressive type for complex domain models as anyone with a typo in one can attest. In UX terms, strings don’t provide any affordances–anything will compile and run (but not work). And in case of misspelling an ARN string, neither your browser nor Google will auto-correct your typos (but soon AI might)!
If you’re into DX, you may notice minor inconsistencies in the field naming: the role carries the suffix “Arn” whereas the source does not, even though both fields require an ARN.
Pry the type system from my cold hands!
Since we dwelled in early OOPSLA days, I recalled an amazing panel discussion at OOPSLA 2005) where the creators of structured design and UML had a go at modeling languages. Just for kicks, here’s one of Kent Beck’s quotes:
People who could not do a decent job with structured design went to objects so no one would notice.
I might be one of those people as I clearly went to objects, having spent a good part of my career building large domain models in Java, for example for mobile advertising. Although it is possible to represent domain concepts in data structures, an object-oriented language brings more expressiveness tools like interfaces, inheritance, or composition. Those constructs come in quite handy because they provide affordances, meaning they suggest correct usage without reading the manual.
My background makes it unsurprising that I favor object-orientated languages for applications and automation. Within the automation category CDK is once again close to home (Pulumi being another popular choice), so here’s the equivalent CDK code, this time reading from a DynamoDB stream source (again abbreviated, full source on GitHub):
const pipe = new CfnPipe(this, 'pipe', {
roleArn: pipeRole.roleArn,
source: ordersTable.tableStreamArn!,
sourceParameters: {
dynamoDbStreamParameters: {
startingPosition: 'LATEST'
},
target: ordersEventBus.eventBusArn,
});
CDK TypeScript is also stringly typed: role, source, and target are strings! It’s time to echo my recent slogan:
I didn’t spend 20 years in the industry to be coding without a type system by counting spaces
An, no I didn’t mean Python but popular cloud automation languages. The default CDK constructs mimicking existing CloudFormation resources has led some people to conclude that OO for cloud automation isn’t particularly useful. I couldn’t disagree more—no one could take the type system from me! However, I can see where folks are coming from and it’s not a matter of language design but one of common usage. Time for another punchy slogan:
If you use CDK without actually taking advantage of object orientation (incl. types), then you’re indeed better off using YAML.
Translated into CDK parlance, this means that CDK without Level 2 or 3 constructs isn’t particularly useful. Luckily, a Level 2 construct for Pipes is in the works that captures the service behavior in a domain model, including strong (not string) types for sources and transformations.
Affordances with strongly typed cloud automation
Still, imho we could be doing much more to harness the power of object orientation and type systems to make programming the cloud easier. Coming back to the noses and notches, one would easily imagine a set of base types or interfaces like this pseudo-syntax (I am being intentionally vague here) :
interface Source {} // source that can be polled
interface Sink {} // target that you can push messages to
class Pipes {
Source source;
Sink target;
}
class EventBridge : Sink {}
class SQS: Sink, Source {}
Using this rather primitive type system, your IDE can already tell you which connector works with which source and target. One could take this approach a step further and wrap these types into a fluent API that guides the programmer towards valid combinations by simply hitting CTRL-SPACE.
My aspiration would be:
Why wait for deployment to tell you that things aren’t working if the type system could have done so?
A type system provides the tightest inner loop for developers: a red underline just as you type. If the type system takes out many of the simple error sources before you deploy, deployment times would be less of a bottleneck. Apparently, there’s lots of interesting work ahead in this area!
Epilogue: Nature is telling me…
The Software Architect Elevator includes a favorite Dick Guindon quote:
Writing is nature’s way of letting you know how sloppy your thinking is.
Well, this post tells me that my thinking is still pretty sloppy. But I hope you gained some insight into the importance of domain models for programming distributed cloud systems. Thanks for reading!
Oh, and one more thing: If you are keen to see the power of domain modeling in action, take a peek at Markus Voelter’s new book How to Understand Almost Anything. Behind the click-baity title lies an insightful summary of his decades of experience in modeling complex domains.