
Post Views: 7,347
With the rise of OpenAI’s ChatGPT, there is a huge momentum to experiment, ideate, and create innovative solutions unleashing the power of ChatGPT. This blog’s focus is to explore the currently available possibilities to customize OpenAI’s ChatGPT as per your enterprise’s requirements.
#1 — Static & Dynamic Prompt Engineering
This is the foundational step to generate relevant and contextual information from the ChatGPT model to shape the conversation. Prompts can be of the following types as well (click here for a catalog of examples by OpenAI, and click here for a collection of prompt examples):
- Instructional: telling the model what you are expecting
- Completion: telling the model to finish the sentence
- Demonstration: showing the model example of what you want
At a high level, there are two sets of approaches for generating a prompt:
- Static Prompt: You use a well-structured prompt as per your need at the beginning of the conversation but the prompt is not auto-generated or contains user-specific information. Here is an example:
I want you to act as a linux terminal. I will type commands and you will reply with what the terminal should show.
I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. - Dynamic Prompt: The prompt gets dynamically generated by a component, which takes care of context as well as injects user or enterprise data into a prompt as shown below. Dynamic Prompt Generator in the below example:
— Fetches data through the Enterprise API (step 2)
— Generates the prompt based on the contextual data
— Calls the Chat Completions API (step 3)

Furthermore, as prompt engineering, is a continuously evolving field — there are novel techniques being shared by the community (see snapshot below — will deep-dive into techniques as a separate topic):
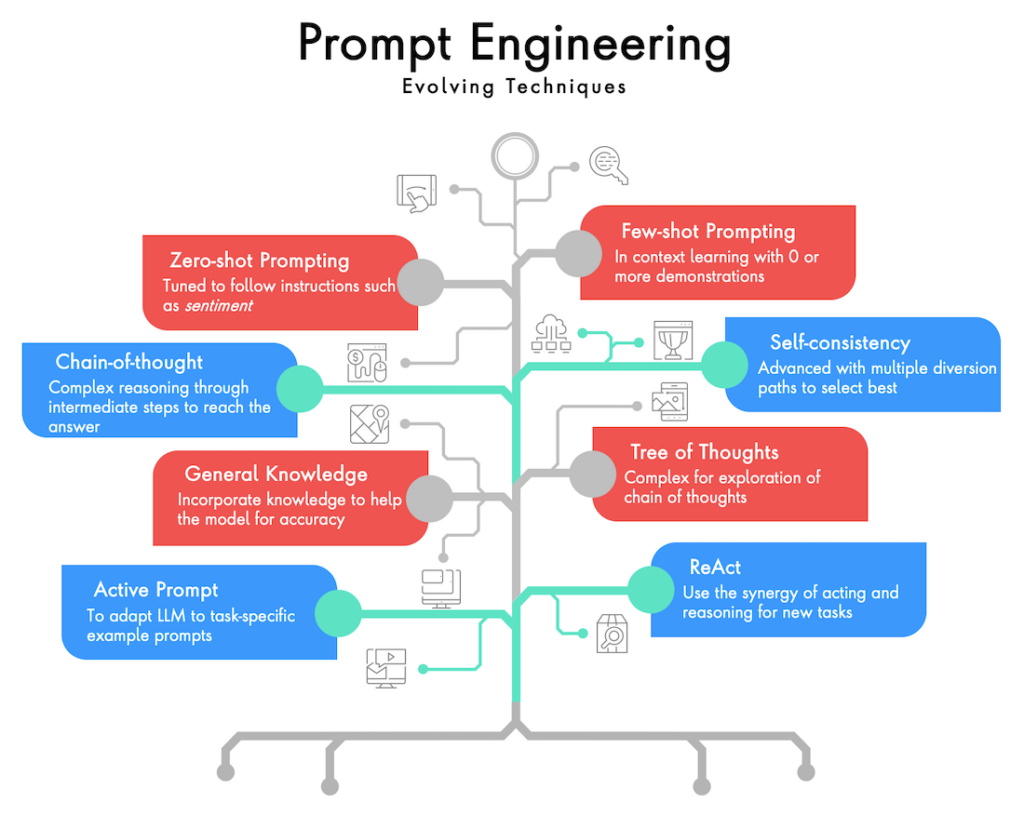
#2 — Embedding Your Data with Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation compliments LLMs with enterprise-specific data with minimal exposure of data to a public model with increasing reliability of the generated responses, and it helps to mitigate the problem of hallucination. You can consider it as a memory (similar to RAM) to hold the information to augment the process of generating the response from ChatGPT using the enterprise-managed datastore. Datastore can be a specialized vector database (such as Milvus, Weaviate, Pinecone, Chroma) or an existing relational database system (such as PostgreSQL with pgvector), or a document database (such as ElasticSearch) having semantic-search capabilities.
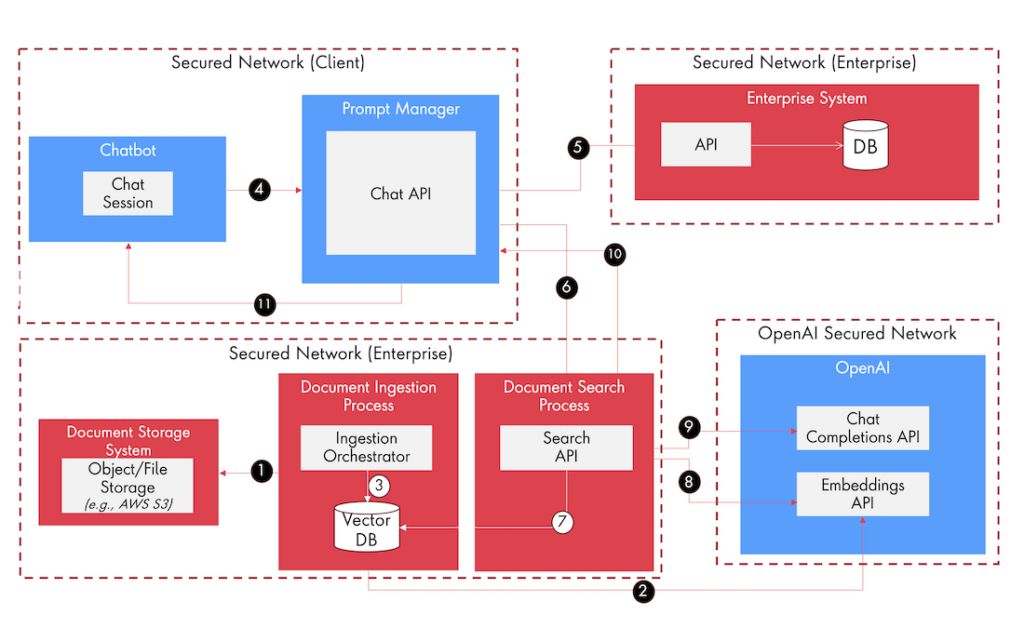
The process to apply embeddings using enterprise data has been illustrated below, which can be customized as per the context:
- Step 1: The document ingestion process gets kicked off with a notification of a new document from a document storage system such as AWS S3.
- Step 2: The ingestion orchestrator component will call OpenAI’s Embeddings API to generate embeddings from the data.
- Step 3: The ingestion orchestrator will store the embeddings data in a vector database.
- Step 4: The user starts to interact with Chatbot and establishes the chat session and the prompt manager component gets triggered.
- Step 5: The chatbot will invoke the Chat API endpoint. Chat API has Prompt Management capabilities. The prompt manager will generate a dynamic or static prompt applying prompt engineering practices and invoking an enterprise API to get the required data (if needed).
- Step 6: The prompt manager will call the Search API, which can also add capabilities of full-text search. Search API.
- Step 7: Search API fetches data from the vector database applying semantic search capabilities.
- Step 8: Search API invokes OpenAI’s Embedding API to get the embedding based on the query text. This embedding will be used to query the vector database.
- Step 9: Search API invokes OpenAI’s Chat Completions API along with content retrieved from searching the vector database and gets the response as per the prompt.
- Step 10: The Chat API, gets the response from the Search API and applies any additional check from a moderation or legal/compliance perspective (if required).
- Step 11: The Chatbot gets the final response from the overall system.
#3 — Fine-tuned Model with Your Enterprise Data
Fine-tuning a model is a complex process to customize the model and as per OpenAI:
Fine-tuning lets you get more out of the models available through the API by providing: Higher quality results than prompt design, Ability to train on more examples than can fit in a prompt, Token savings due to shorter prompts, Lower latency requests.
Note that fine-tuning is only applicable to limited models such as davinci, curie, babbage, and ada.
The process for fine-tuning has been outlined below:
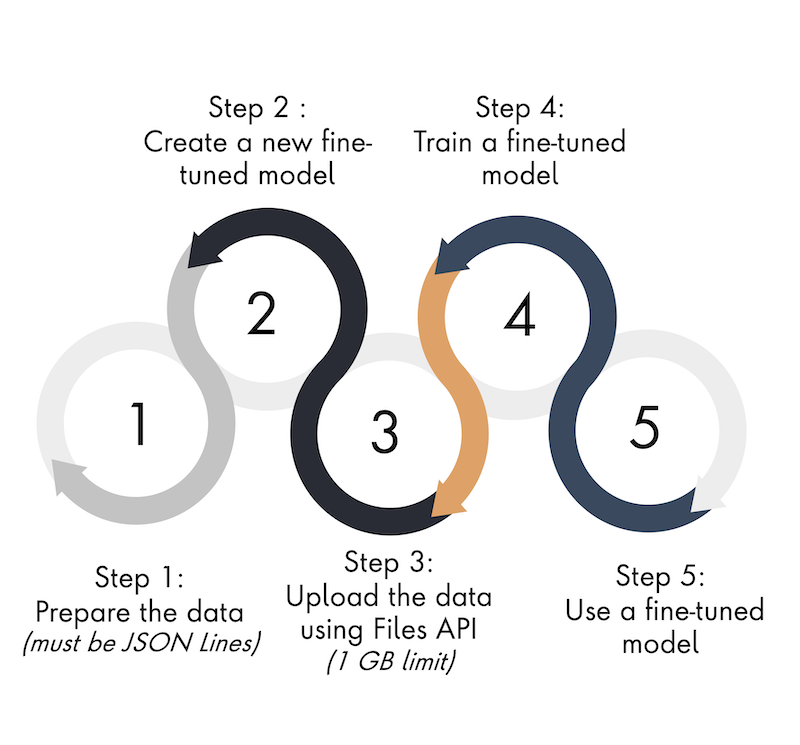
#4 — Extend the functionality with ChatGPT Plugins
ChatGPT Plus supports Plugins to extend the functionality of ChatGPT as a third-party provider. As defined by OpenAI:
Plugins are tools designed specifically for language models with safety as a core principle, and help ChatGPT access up-to-date information, run computations, or use third-party services.
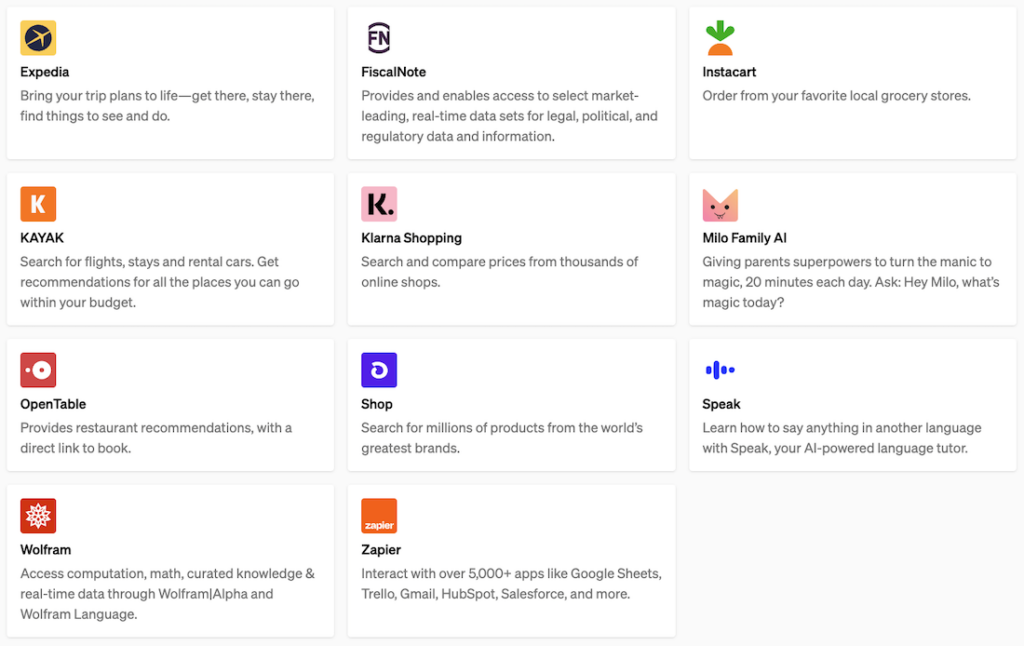
Here is a quick snapshot of plugins available for ChatGPT:
To conclude, this article highlighted techniques to customize OpenAI’s ChatGPT as per the enterprise requirements. Note that the techniques and steps involved are evolving with require due consideration as per the context. Feel free to reach out to me for further discussions.
References:
Related Articles
Top Ten Technology Trends for 2023
Top 10 Tips For A Modern Software Architect
Evolution of Microservices Frameworks in Java